La Road Map del Web Semantico
Questo documento è la traduzione del documento Semantic Web Road Map di Tim Berners-Lee. Il documento originale è su http://www.w3.org/DesignIssues/Semantic.html.
Ringrazio Tim Berners-Lee e Ian Jacobs per aver concesso l'autorizzazione alla traduzione.
Traduzione di Pasquale Popolizio.
Tim Berners-Lee Data: Settembre 1998. Data dell'ultima modifica: 1998/10/14 20:17:13
Stato del documento: Un tentativo di dare un piano di alto-livello all'architettura del World Wide Web Semantico. Stato di edizione: Bozza. I commenti sono benvenuti.
La Road Map del Web Semantico
Una Road Map per il futuro, un piano di architettura validato solo da esperimenti.
Questo documento è stato scritto, come parte di una road map necessaria per il futuro del design del Web, da un'altezza di 20.000 piedi. E' stato sviluppato da una visione d'insieme di Architettura per un'area che richiedeva maggiori elaborazioni.
Necessariamente, da 20.000 piedi, le cose grandi sembrano davvero piccole. Riguarda l'architettura, poi, nel senso di come le cose, in maniera fiduciosa, si uniscono. Così possiamo riconoscere che, mentre potrebbe cambiare molto lentamente, questo rappresenta anche un documento che vive e quindi si modifica nel tempo.
Questo documento rappresenta un piano per raggiungere, ed avere connesse sul Web, un gruppo di applicazioni per i dati in un modo da formare un Web di dati logicamente consistente (semantic web).
Introduzione
Il Web fu disegnato come uno spazio di informazioni, con l'obiettivo di essere utile non solo per la comunicazione uomo-uomo, ma affinché anche che le macchine potessero avere la possibilità di partecipare e dare il loro contributo. Uno dei maggiori ostacoli è stato il fatto che la maggior parte dell'informazione sul Web è disegnata per essere fruita dall'uomo, ed anche se essa fosse derivata da un database con un significato ben definito (almeno per alcuni termini) per le sue colonne, la struttura dei dati non è riconoscibile per un robot che naviga il Web. Tralasciando il problema dell'intelligenza artificiale delle macchine di agire come le persone, l'approccio del Web Semantico, invece, sviluppa linguaggi per esprimere le informazioni in una forma accessibile e processabile da una macchina.
Questo documento fornisce una road map, una sequenza, per un'introduzione progressiva della tecnologia che ci porti, passo dopo passo, dal Web di oggi ad un Web nel quale il ragionamento delle macchine sarà frequente e potente in modo devastante.
Esso segue la nota sull'architettura del Web, che definisce le decisione esistenti sul design ed i principi per i quali è stata realizzata per quella data.
Informazioni riconoscibili dalle macchine: Il Web Semantico
Il Web Semantico è una ragnatela di dati, in qualche modo riconducibile ad un database globale. Le ragioni per creare una tale infrastruttura vengono esplicitate altrove [ragionamenti sul futuro del Web e altro], qui delineo l'architettura così come la vedo.
Il modello di dichiarazione base
Quando guardiamo ad una possibile formulazione di un Web universale di dichiarazioni semantiche, il principio di design minimalista richiede che esso sia basato su un modello comune di grande generalità. Solo quando il modello comune sia generale ogni applicazione potenziale potrà essere mappata nel modello. Il modello generale è il Resource Description Framework.
Vedi il Modello RDF ed la Specifica di Sintassi
In generale, tutto ciò è molto semplice. Per essere semplici non c'è niente che si possa fare con il modello stesso senza trasferire molte cose in superficie. Il modello base contiene proprio il concetto di dichiarazione, e il concetto di citazione - fare dichiarazioni su dichiarazioni. Questo è introdotto perché (a) esso sarà necessario in ogni modo in seguito e (b) la maggior parte delle prime applicazioni RDF riguardano dati circa i dati ("metadata") nei quali le dichiarazioni su dichiarazioni sono di base, ancorché prima che logiche. (A causa delle applicazioni obiettivo dell'RDF, le dichiarazioni sono parte della descrizione di alcune risorse, quella risorsa è spesso un parametro implicito e la dichiarazione è riconosciuta come una proprietà di una risorsa).
Per quanto dicano i matematici, il linguaggio a questo punto non ha negazione o implicazione, ed è perciò molto limitato. Dato un gruppo di fatti, è facile dire se una prova esiste o non per una data domanda, perché né i fatti né le loro domande possono avere abbastanza potere per rendere il problema insolubile.
A questo livello le applicazioni sono numerose. La maggior parte delle applicazioni per la rappresentazione dei metadati può essere gestita a questo livello dall'RDF. Esempi sono informazione card index (il Dublin Core), Privacy information (P3P), associazioni di fogli di stile con documenti, etichettature di diritti di proprietà intellettuale e etichette PICS. Qui stiamo parlando di rappresentazione di dati, che è tipicamente semplice: non linguaggi per esprimere query o regole di inferenza.
I documenti RDF a questo livello non hanno un grande potere, ed a volte è poco evidente il perché ci si dovrebbe preoccupare di mappare un'applicazione in RDF. La risposta è che ci aspettiamo che questi dati, sebbene limitati e semplici all'interno di un'applicazione, siano combinati, in seguito, con dati derivanti da altre applicazioni in un Web. Le applicazioni che girano sull'intero Web devono essere in grado di usare una struttura comune per combinare informazioni da tutte queste applicazioni. Per esempio, la logica di controllo di accesso può utilizzare una combinazione di dati sull'appartenenza sia privati che pubblici e tipi di informazione di dati per permettere o negare un accesso. Le query possono permettere in seguito espressioni logiche più potenti che si riferiscono a dati da domini, nei quali, individualmente, il linguaggio di rappresentazione dei dati non risulta molto espressivo. Lo scopo di questo documento è in parte quello di mostrare il piano con il quale questo potrebbe accadere.
Il livello di Schema
Il modello base dell'RDF ci permette di fare molto in teoria, ma non ci fornisce molti strumenti. Esso ci dà un modello di dichiarazioni e citazioni sul quale possiamo mappare i dati in ogni nuovo formato.
Abbiamo bisogno di un livello di schema per dichiarare l'esistenza di una nuova proprietà. Abbiamo bisogno, nello stesso tempo, di dire qualcos altro su questo. Vogliamo avere la possibilità di restringere il modo di utilizzo. In genere vogliamo restringere i tipi di oggetti ai quali si può applicare. Queste meta-dichiarazioni rendono possibile realizzare verifiche rudimentali su un documento. Così come in SGML la "DTD" ci permette di verificare se gli elelemnti sono stati usati nelle posizioni appropriate, nell'RDF uno schema ci permetterà di verificare se, per esempio, una patente ha il nome di una persona, e non il modello di auto, come suo "nome".
Non mi è chiaro esattamente quali primitivi devono essere introdotti, e se del linguaggio più utile possa essere definito a questo livello senza anche definire il livello successivo. Al momento esiste un gruppo di lavoro sull'RDF Schema che discute sull'argomento. Il linguaggio di schema tipicamente fa semplici dichiarazioni sulle combinazioni permesse. Se una DTD SGML viene utilizzata come modello, lo schema può essere in un linguaggio con forza molto limitata. Le restrizioni espresse nel linguaggio di schema sono facilmente espanse in un più potente livello logico di espressioni (il livello successivo), ma si può scegliere, a questo punto, allo scopo di limitare il potere, di non farlo. Per esempio, si può dire in uno schema che una proprietà foo è unica. Espansa, cioè che per ogni x, se y è la foo di x, e z è la foo di x, poi y è uguale a z. Questo usa espressioni logiche che non sono disponibile a questo livello, ma che sono OK fin quando il linguaggio di schema è, al momento, suscettibile di essere manipolato solo da motori specializzati di schema, e non da un motore che possiede capacità di generale ragionamento.
Quando facciamo questa cosa con un linguaggio - e penso che questo sarà molto comune - dobbiamo fare attenzione che il linguaggio sia ancora ben definito logicamente. In seguito, potremmo voler realizzare inferenze che possono essere fatte solo riconoscendo e capendo la semantica del linguaggio di schema in termini logici, e combinandola con altre informazioni logiche.
Il linguaggio di conversione
Una necessità di lavoro sui namespace per possibilità di evoluzione è quello che che uno deve, con conoscenza di RDF a qualsiasi livello, essere in grado di seguire le regole per convertire un documento in uno schema RDF in un altro (significa presumibilmente che qualcuno ha una capacità innata di capire su come procedere).
Dal principio del potere minimo, questo linguaggio può in realtà essere realizzato per avere implicazioni (regole di inferenza) senza avere negazione. (Ciò potrebbe sembrare una sottigliezza, quando in realtà si può facilmente scrivere una regola che definisce inferenza da una dichiarazione A di un'altra dichiarazione B che appare essere falsa, anche se il linguaggio non ha la possibilità di indicare "Falso". Comunque, ancora formalmente il linguaggio non deve avere il potere di scrivere un paradosso, il che conforta alcune persone. In seguito, però, come il linguaggio diverrà più espressivo, non dipenderemo su una abilità inerente di fare dichiarazioni paradossali, ma su applicazioni che in maniera specifica limiteranno il potere espressivo di particolari documenti. Gli schemi forniscono un posto adatto a descrivere queste restrizioni).
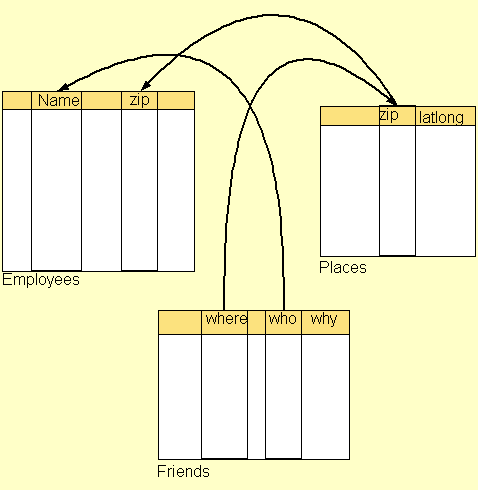 Un semplice esempio dell'applicazione di questo livello è quando due database, costruiti in modo indipendente e poi posti sul Web, vengono collegati da collegamenti semantici che permettono query su uno da convertire in query sull'altro. Qui, qualcuno ha annotato che "where" nella tabella friends e "zip" nella tabella places hanno lo stesso significato. Qualcun'altro ha annotato che "zip" nella tabella places ha lo stesso significato di "zip" nella tabella employees, così come illustrato mediante le frecce. Con questa informazione, una ricerca per ogni impiegato chiamato Fred con il codice postale 02139 può essere ampliata da employees fino ad includere friends. Per tutto questo è necessaria la proprietà RDF "equivalent".
Un semplice esempio dell'applicazione di questo livello è quando due database, costruiti in modo indipendente e poi posti sul Web, vengono collegati da collegamenti semantici che permettono query su uno da convertire in query sull'altro. Qui, qualcuno ha annotato che "where" nella tabella friends e "zip" nella tabella places hanno lo stesso significato. Qualcun'altro ha annotato che "zip" nella tabella places ha lo stesso significato di "zip" nella tabella employees, così come illustrato mediante le frecce. Con questa informazione, una ricerca per ogni impiegato chiamato Fred con il codice postale 02139 può essere ampliata da employees fino ad includere friends. Per tutto questo è necessaria la proprietà RDF "equivalent".
Il Livello logico
Il livello successivo è il livello logico. Abbiamo bisogno di modi di scrivere la logica nei documenti per permettere cose come regole per la deduzione di un tipo di documento da un documento di un altro tipo; la verifica di un documento rispetto ad un gruppo di regole di auto coerenza; e la risoluzione di una query con la conversione da termini sconosciuti in termini conosciuti. Dato che già abbiamo la citazione nel linguaggio, il livello successivo è la logica predicata (not, and, etc) e la successiva quantificazione di livello (for all x,y(x)).
Le applicazioni di RDF a questo livello sono generalmente limitate solo dall'immaginazione. Un semplice esempio dell'applicazione di questo livello è quando due database, costruiti in modo indipendente e poi posti sul Web, sono collegati da collegamenti semantici che permettono query su uno per convertire in query sull'altro. Molte cose che possono sembrare aver bisogno di un nuovo linguaggio diventano improvvisamente semplicemente una questione di scrivere l'RDF appropriato. Una volta che hai un linguaggio che ha il grande potere di calcolo predicato con citazione, poi, quando si definisce un nuovo linguaggio per un'applicazione specifica, sono necessarie due cose:
- Bisogna contare sul potere (limitato) di un motore che possiede capacità di ragionamento che il ricevitore deve avere, e definire un sottogruppo di RDF che sia suscettibile di essere capito;
- Bisogna probabilmente voler definire alcune funzioni abbreviate per trasmettere efficacemente espressioni all'interno del gruppo dei documenti all'interno del linguaggio ristretto.
Se sei scettico, vedi anche:
- Cosa non è il Web Semantico - risposte ad alcune FAQ
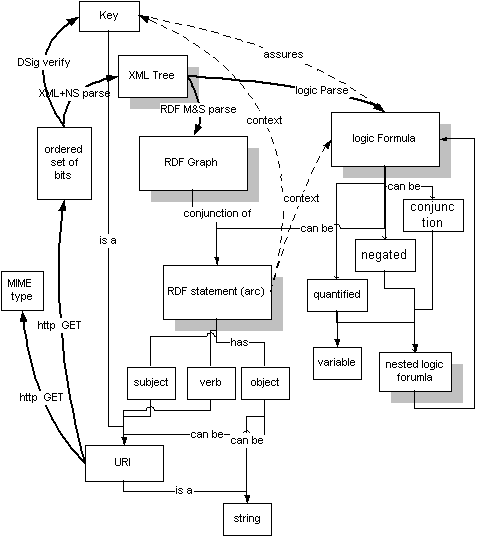
La mappa "del metrò" in basso mostra un loop chiave nel Web semantico. La parte Web, sulla sinistra, mostra come un URI, usando HTTP, viene trasformato in una rappresentazione di un documento come una stringa di bit con un tipo di MIME. Esso poi viene elaborato (parsed) in XML e poi in RDF, per produrre un grafico RDF o, ad un livello logico, una formula logica. Sulla parte destra, la parte Semantica, mostra come il grafico RDF contiene un riferimento all'URI. E' la fiducia dalla chiave, combinata con il significato delle dichiarazioni contenute nel documento, che può portare un motore di Web Semantico a dereferenziare un altro URI.
Validazione di prova - un linguaggio per prova
Il modello RDF non dice niente sulla forma del motore che possiede capacità di ragionamento, ed è ovviamente una questione aperta, poiché non esiste un algoritmo perfetto per rispondere alle domande - o, in genere, a trovare le prove. A questo punto dello sviluppo del Web Semantico, però, non affrontiamo il problema. La costruzione di una prova per la maggior parte delle applicazioni è fatta in accordo con alcune regole ristrette, e tutto ciò che l'altra parte deve fare è validare una prova generale. Ciò è banale.
Per esempio, quando qualcuno è autorizzato ad accedere ad un sito Web, questi potrebbe dare un documento che spiega al server Web perché dovrebbe avere accesso. La prova sarà una catena [DAG] di dichiarazioni e regole di ragionamento con riferimenti a tutto il materiale di supporto.
Lo stesso sarà vero per transazioni che riguardano la privacy, e la maggior parte del commercio elettronico. I documenti spediti nella Rete saranno scritti in un linguaggio completo. Comunque, essi saranno ristretti così che, se soggetti a query, i risultati saranno calcolabili, ed in molti casi essi saranno provati. Il "GET" di HTTP conterrà una prova che il client ha un diritto alla risposta. La risposta sarà una prova che la risposta è l'azione che è stata richiesta.
L'evoluzione regola il Linguaggio
L'RDF al livello logico possiede già il potere di esprimere regole di inferenza. Per esempio, potresti avere la possibilità di dire cose come "Se il codice postale dell'organizzazione di x è y, poi il codice postale dell'ufficio di x è y". Come già sottolineato, sarà anche molto interessante disperdere per il Web tali osservazioni, ma nel breve termine questo non produrrà risultati ripetibili finché non restringiamo l'espressività dei documenti per risolvere particolari problemi di applicazione.
Due fondamentali funzioni che richiediamo ai motori RDF sono:
- per una implementazione di versione n di avere la possibilità di leggere abbastanza schema RDF da poter dedurre come leggere un documento di versione n+1;
- per un'applicazione di tipo A sviluppata indipendentemente da un'applicazione di tipo B che ha stessa o simile funzione di avere la possibilità di leggere e processare abbastanza informazione di schema da permettere di processare i dati dall'applicazione di tipo B.
(Vedi articolo sulla possibilità di evoluzione)
Il livello logico dell'RDF è sufficiente per essere usato come linguaggio per realizare regole di inferenza. Nota che esso non soddisfa l'euristica di ogni particolare motore che possiede capacità di ragionamento, che è un terreno aperto fatto più aperto e produttivo dal Web Semantico. In altre parole, l'RDF permette di scrivere regole ma non dice a nessuno, a questo livello, in quale ordine applicarle.
Dove per esempio uno schema della Biblioteca del Congresso parla di "autore", e la British Library parla di "creatore", un piccolo pezzo di RDF avrebbe la possibilità di dire che per ogni persona x e ogni risorsa y, se x è l'autore (per la Biblioteca del Congresso) di y, poi x è il creatore (per la British Library) di y. Questo è il tipo di regola che risolve i problemi della possibilità di evoluzione. Un processore dove lo troverebbe? Nel caso di un programma che trova una versione 2 del documento e vuole trovare le regole per convertirlo in un documento di versione 1, poi lo schema della versione 2 dovrebbe naturalmente contenere o puntare alle regole. Nel caso di documentazione retrospettiva della relazione fra due schemi inventati indipendentemente, poi naturalmente i puntatori alle regole potrebbero essere aggiunti allo schema, ma se questo non è pratico, poi abbiamo un altro esempio del problema di annotazione. Ciò può essere risolto da indici di terze parti dove si possono ricercare le connessioni fra due schemi. Naturalmente in pratica i motori di ricerca forniscono questa funzione in modo efficace - dovresti chiedere ad un motore di ricerca tutti i riferimenti ad uno schema e verificare i risultati con le regole che corrispondono ai due.
I linguaggi di query
Uno è un linguaggio di query. Una query può essere pensata come una dichiarazione circa il risultato che viene di ritorno. Fondamentalmente, l'RDF al livello logico è sufficiente a rappresentare ciò in ogni caso. Comunque, in pratica un motore di query ha algoritmi specifici ed indici disponibili con i quali lavorare, e può perciò rispondere a tipi specifici di query.
Esso può naturalmente in pratica sviluppare un vocabolario che aiuta in ciascuno dei due modi:
- Permette di esprimere tipi di query comuni e potenti succintamente con poche pagine di matematica, o
- Permette di esprimere certe query ristrette, che sono interessanti perché hanno certe proprietà di calcolo.
L'SQL è un esempio di linguaggio che fa entrambe le cose.
E' chiaramente importante che il linguaggio di query sia definito in termini di logica RDF. Per esempio, per fare una query ad un server per un autore di una risorsa, si dovrebbe chiedere con una dichiarazione del tipo "x è l'autore di p1" per qualche x. Per richiedere un elenco completo di tutti gli autori, si dovrebbe richiedere un gruppo di autori così che ogni autore sia nel gruppo e ognuno nel gruppo sia un autore. E così via.
In pratica, la diversità di algoritmi nei motori di ricerca sul Web, algoritmi che cercano prove in sistemi logici pre-web suggerisce che in un Web semantico ci saranno molte forme di agenti che avranno la possibilità di fornire risposte a differenti forme di query.
Un utile passo, la specifica di query particolari per motori, per esempio ricerche ad un definito e finito livello di ricerca in un definito sottogruppo del Web (come un sito Web). Naturalmente ci potrebbero essere varie alternative per differenti occasioni.
Un altro "metastep" è la specifica di un linguaggio di descrizione di motore di query - in genere una specifica del tipo di query che il motore può ritornare in un modo generale. Questo aprirebbe la porta ad agenti che collegano insieme ricerche ed inferenze fra molti motori intermedi.
La firma digitale
La crittografia con chiave pubblica è una tecnologia straordinaria che cambia completamente ciò che è possibile. Mentre si può aggiungere un blocco di firma digitale come decorazione su un documento esistente, tentativi di aggiungere la logica della fiducia come la glassa sulla torta di un sistema di ragionamento sono stati ristretti a sistemi limitati nella loro generalità. Affinchè un sistema che ragiona possa accettare modelli di fiducia, il modello logico comune richiede un'estensione per includere le chiavi con le quali sono state firmate le dichiarazioni.
Come tutta lo logica, la base di questo può non sembrare attraente in prima battuta finché non si vede che cosa può essere costruito al vertice. Questa base è l'introduzione di chiavi come oggetti di prima classe (dove l'URI può essere un valore letterale di una chiave pubblica), e un'introduzione di un ragionamento generale sulle dichiarazioni attribuibili alle chiavi.
In un'implementazione, questo significa che i motori che possiedono capacità di ragionamento dovranno essere legati al sistema di verifica della firma. I documenti saranno processati non proprio in alberi di dichiarazioni, ma in alberi di dichiarazioni su chi ha firmato quelle dichiarazioni. La validazione della prova, per regole di inferenza, verificherà la logica, ma per dichiarazioni per le quali è stato firmato un documento, verificherà la firma.
Il risultato sarà un sistema che può esprimere e ragionare sulla relazione fra tutti i sistemi di fiducia e di sicurezza basati su chiave pubblica.
La firma digitale diventa interessante quando l'RDF viene sviluppato al livello dove esiste un linguaggio di prova. Comunque, può essere sviluppato in parallelo con l'RDF per la maggior parte.
Nel W3C, l'input al lavoro sulla firma digitale arriva da molte direzioni, incluse l'esperienze con le etichette "pics" firmate DSig1.0, e vari contributi per documenti firmati in maniera digitale.
Indici dei termini
Dato un ampio Web semantico di dichiarazioni, l'odierna (1998) tecnologia dei motori di ricerca applicata alle pagine HTML presumibilmente tradurrà direttamente in indici fatti non di parole, ma di oggetti RDF. Questo permetterà una ricerca del Web molto più efficiente come se esso fosse un gigantesco database, piuttosto che un gigantesco libro.
Il requisito della traduzione da Versione A a Versione B è stato ora raggiunto, e così quando esistono due database come per esempio grandi array di file RDF (probabilmente virtuali), poi, anche se gli schemi iniziali possono non essere stati gli stessi, una documentazione retrospettiva della loro equivalenza permetterebbe ad un motore di ricerca di soddisfare query di ricerca in entrambi i database.
I motori del futuro
I motori di ricerca che indicizzano le pagine HTML trovano sì risposte alle ricerche e coprono una grossa parte del Web, ma poi rispondono con molti risultati non appropriati. Non esiste una nozione di "esattezza" per tali ricerche. Di contro, i motori logici sono stati in genere capaci di restringere i loro output a quella che è probabilmente la risposta corretta, ma hanno sofferto dall'impossibilità di rovistare nella massa di dati intrecciati per costruire risposte valide. L'esplosione combinatoria di tener conto di tutte le possibilità non è stata facilmente risolta.
Comunque, il piedistallo sul quale sono stati posti i motori di ricerca può portarci ad riesaminare, qui, le nostre assunzioni. Se un motore del futuro combina un motore che possiede capacità di ragionamento con un motore di ricerca, esso può essere in grado di ricavare il meglio dai due mondi, e può essere in grado realmente di costruire prove in un certo numero di casi di impatto elevato. Esso sarà in grado di ricercare fra indici che contengono un elenco molto completo di tutte le ricorrenze di un determinato termine, e poi usare la logica per eliminare tutto tranne quelle che possono essere usate per la risoluzione di un dato problema.
Così, mentre niente potrà eliminare l'esplosione di possibili combinazioni, molti problemi di vita reale possono essere risolti usando solo pochi (diciamo due) passi di inferenza nel selvaggio Web, essendo, il resto del ragionamento in uno stato nel quale sono date le prove, o ci sono algoritmi ristretti e ben conosciuti in modo calcolabile. Mi aspetto anche un incentivo commerciale per sviluppare motori ed algoritmi che affrontano efficacemente specifici tipi di problemi. Questo può portare a realizzare caches di risultati intermedi molto vicini agli indici dei motori di ricerca di oggi.
Nonostante non ci sia ancora una macchina che può garantire risposte a domande arbitrarie, può essere cetamente da ricordare il potere di rispondere a domande reali che rappresentano le cose della nostra vita giornaliera e specialmnete del commercio.
Della stessa serie di documenti:
- What the Semantic Web is not - risposte ad alcune FAQ di coloro che sono scettici
- Evolvability: proprietà del linguaggio per evoluzione della tecnologia
- Web Architecture from 50,000 feet
Riferimenti
The CYC Representation Language
Knowledge Interchange Format (KIF)
Ringraziamenti
Questo documento è basato su discussioni all'interno del gruppo del W3C, e varie compagnie membri del W3C. Grazie anche a David Karger e Daniel Jackson del MIT/LCS.